[스팀몬스터] rule 별 사용가능한 카드 찾아보기
스몬에서는 게임의 재미를 올리기 위하여 ruleset이라는 게임 조건이 있습니다. ruleset에 따라서 능력이 제한되기도 하고, 심지어는 사용할 수 없는 카드도 있습니다. 공홈에서 게임을 하는 경우에는 화면에 보이는 카드 중 선택을 하면 되기 때문에 큰 문제는 없지만 자동으로 팀을 만들기 위해서는 사용할 수 있는 카드에 대한 정보가 아주 중요합니다. 만약 사용할 수 없는 카드를 사용하는 경우에는 실격패를 당하기 때문입니다.
rule을 잘 읽어보고 조건에 맞는 카드를 고를 수도 있겠지만, 조금 색다른 방법으로 접근을 해 보았습니다.
요즘 인기있는 AI는 딥러닝이라하는 심층망을 사용하는데요. 여기에서 가장 중요한 것은 데이터입니다. 좋은 데이터만 많으면 원하는 결과를 얻을 수 있다는 접근법입니다.
그래서 rule 별로 사용가능한 카드도 규칙을 만들지 않고, 데이터를 기반으로 뽑아내는 방법을 시도해보았습니다.
우선 데이터를 확보해야합니다.
https://kr.peakmonsters.com/에 가보면 '베틀체인' 메뉴가 있습니다. 여기에 가 보면 최근 게임 내용을 볼 수 있는데요. 최근 게임 내용을 볼 수 있는 API를 찾아보겠습니다.
이번 수능 점수 유출과 관련된 내용이기도 합니다. 웹페이지의 소스를 모두 볼 수 있기 때문에 본인이 원하는 결과를 가져올 수도 있습니다.
개발자 모드에서 접속을 해보니 아래와 같이 어떤 api를 이용하였는지 확인이 가능합니다.
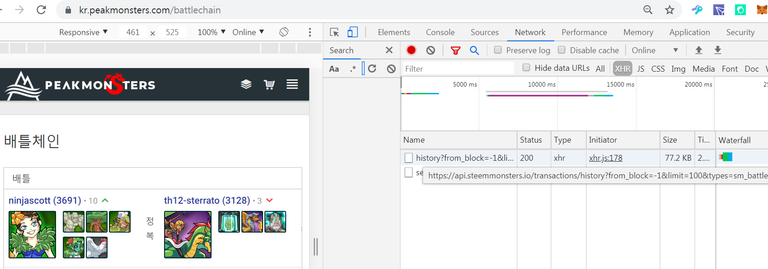
링크가 아래와 같습니다. from_block 값을 적절히 바꾸면 과거 데이터도 모두 확인이 가능합니다.
https://api.steemmonsters.io/transactions/history?from_block=-1&limit=100&types=sm_battle
이 API를 바탕으로 ruleset 별로 사용한 카드를 뽑아내는 파이썬 프로그램을 만들어 보았습니다.
# rules에 해당 rule 별 monster를 추가
def add_monsters(rules, rule, info) :
info = remove_chicken(info)
if rule not in rules :
rules[rule] = []
mon_len = len(info['monsters'])
for i in range(0, mon_len) :
id = info['monsters'][i]['id']
if id in rules[rule] :
continue
rules[rule].append(id)
return rules
def gather_ruleset_monsters_from_online() :
out_name = "monster_rule_set.txt"
rules = load_json_from_file(out_name)
cmd = "transactions/history?from_block=38780663&limit=1000&types=sm_battle"
battles = get_data_from_sm(cmd, 1)
for battle in battles :
results = json.loads(battle['result'])
if 1 :
id = results['id']
mana = results['mana_cap']
rule = results['ruleset']
details = results['details']
block_num = battle['block_num']
if 'type' in details :
continue
team1 = convert_battle_info(details['team1'])
team2 = convert_battle_info(details['team2'])
if rule.find('|') >= 0 : # | 가 있으면
e_rule = rule.split('|')
add_monsters(rules, e_rule[0], team1)
add_monsters(rules, e_rule[0], team2)
rule = e_rule[1]
rules = add_monsters(rules, rule, team1)
rules = add_monsters(rules, rule, team2)
save_to_file_json(out_name, rules)
gather_ruleset_monsters_from_online()
이 프로그램에서는 최근 1000개의 대전에서 rule 별로 사용한 카드의 id를 저장합니다.
잘 저장되었는지 확인을 해 봐야겠지요. rule과 color를 입력을 주면 해당하는 rule과 splinter에서 사용가능한 카드에 대한 정보를 출력해줍니다.
def print_ruleset_data(given="all", color="all") :
out_name = "monster_rule_set.txt"
rules = load_json_from_file(out_name)
cards = []
for rule in rules :
if given != 'all' :
if given.find(rule) == -1:
continue
for card in rules[rule] :
str_id = str(card)
if color == 'all' or color == CARD_ID_NAME[str_id][3] or 'Gray' == CARD_ID_NAME[str_id][3]:
# ["Spineback Turtle",1,4,"Blue"]
cards.append([CARD_ID_NAME[str_id][3], card, CARD_ID_NAME[str_id][0], CARD_ID_NAME[str_id][2]])
scards = sorted(cards, key = lambda x: (x[0], x[2]), reverse=False) # 0번째가 key
print(rule)
for card in scards :
print(card)
print('total cnt:', len(scards))
return scards
print_ruleset_data("Taking Sides", 'White')
확인을 해보니 많이 부족합니다. 1000 판으로는 부족하군요. 그래서
api의 from_block 값을 감소시키면서 좀 더 돌려봅니다. 약 1만 게임정도 다운받으면서 update를 한 결과입니다.
베타 카드를 이용한 게임은 많기 때문에 스몬에서 확인한 카드와 정확하게 일치합니다. 다만 새로 나온 untamed 카드의 경우에는 몇 장이 빠졌군요.

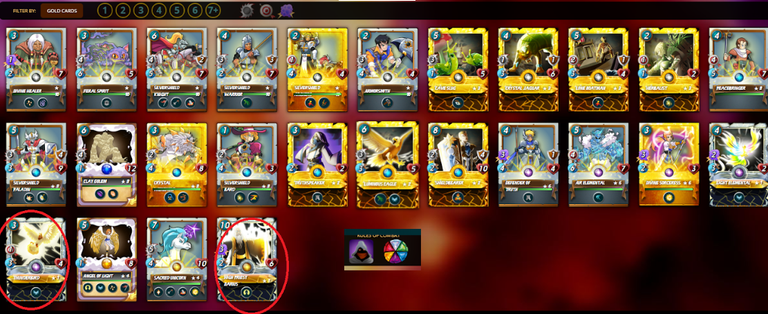
자동프로그램에서 untamed까지는 사용할 필요가 없으니, 팀 구성을 위한 기본 작업은 마무리를 한 것 같습니다.
이제 남은 것은 이길 수 있는 팀 구성을 만드는 것입니다. 이것도 데이터의 도움을 받아야겠죠. 데이터는 있지만 카드가 없으면 문제가 생깁니다. 따라서 만랩인 계정은 문제가 없겠지만 그렇지 않은 계정은 또다른 작업이 필요합니다.
해야할 일이 끝이 없군요. 언제 마무리할 수 있을지....
오오~~ 이 방법 저도 생각하고만 있었는데...
제가 카드가 없는게 많다보니 덱을 일일이 짜야 하나 싶다가.. 그냥 대전정보에서 제가 가지고 있는 카드를 사용한 전투 정보만을 뽑아내면 될것 같다는 생각을 했었거든요.
그나저나 다시 코딩 좀 해야 하는데... 요즘 너무 건강만 생각하고 있네요 ㅎㅎㅎ
파이팅!!!
건강 먼저 ㅎ
Posted using Partiko Android
naha님이 tradingideas님의 이 포스팅에 따봉(7 SCT)을 하였습니다.